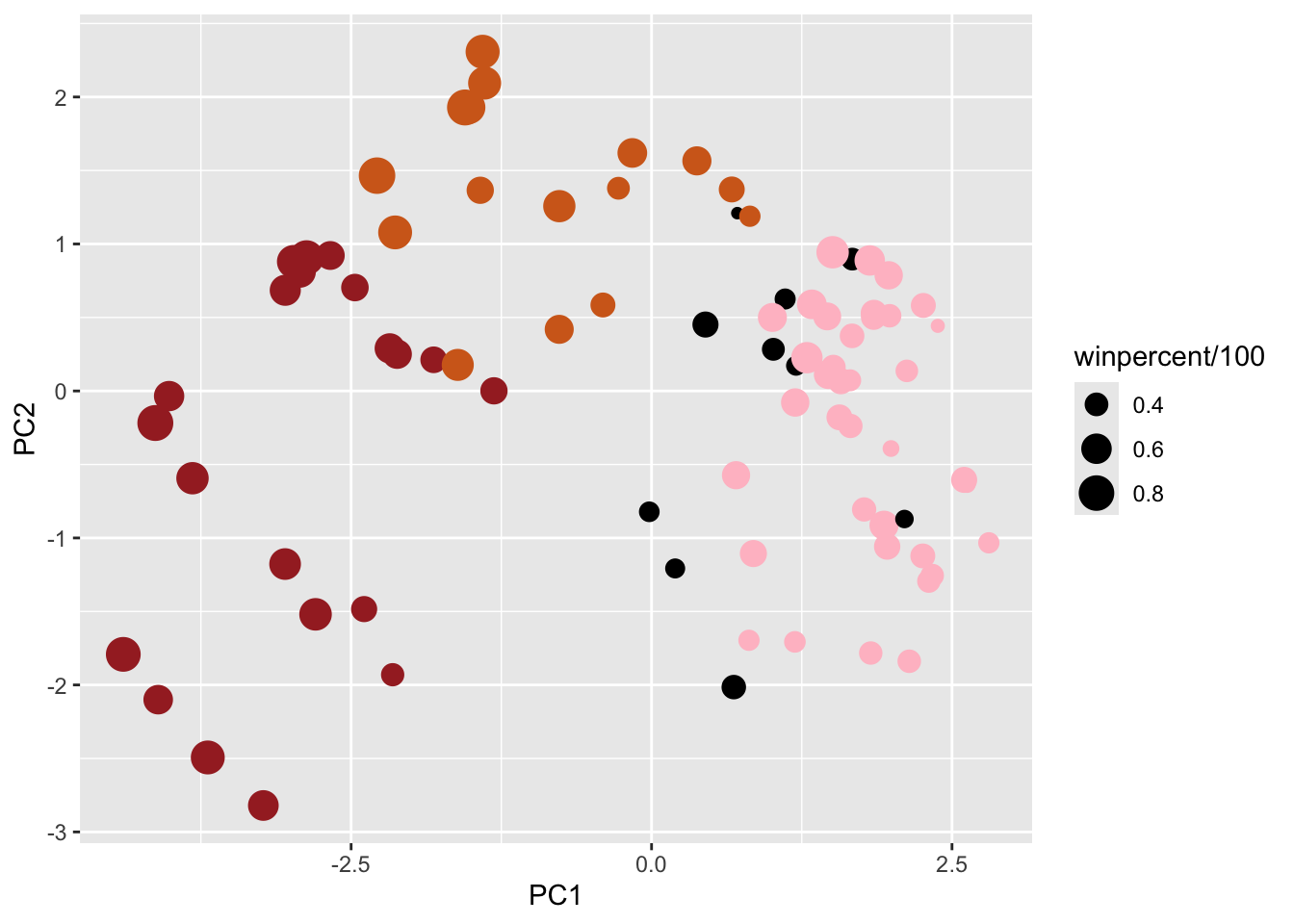
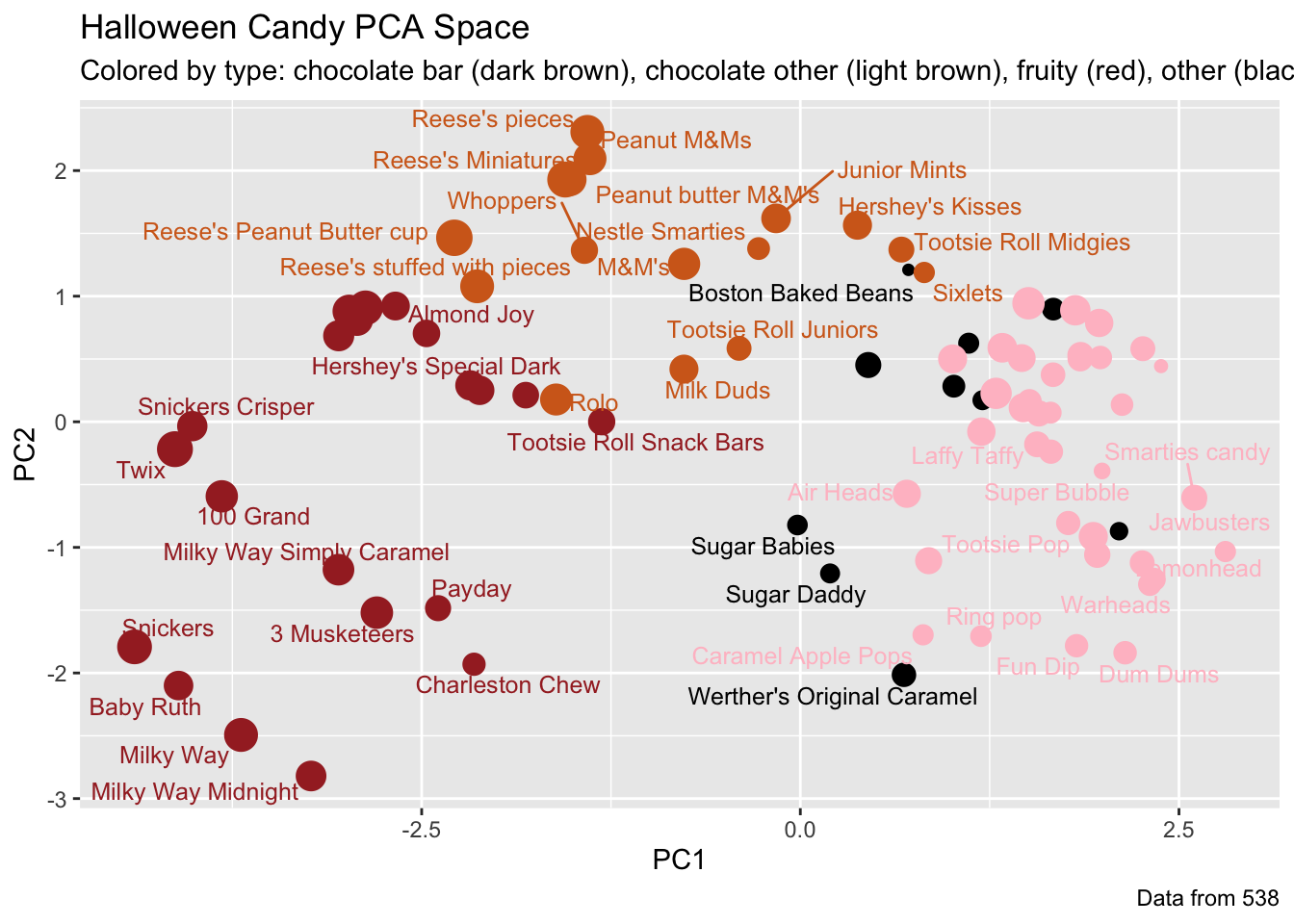
In today’s mini-project we will analyze candy data with ggplot, basic statistics, correlation analysis and principal component analysis methods we have been learning thus far.
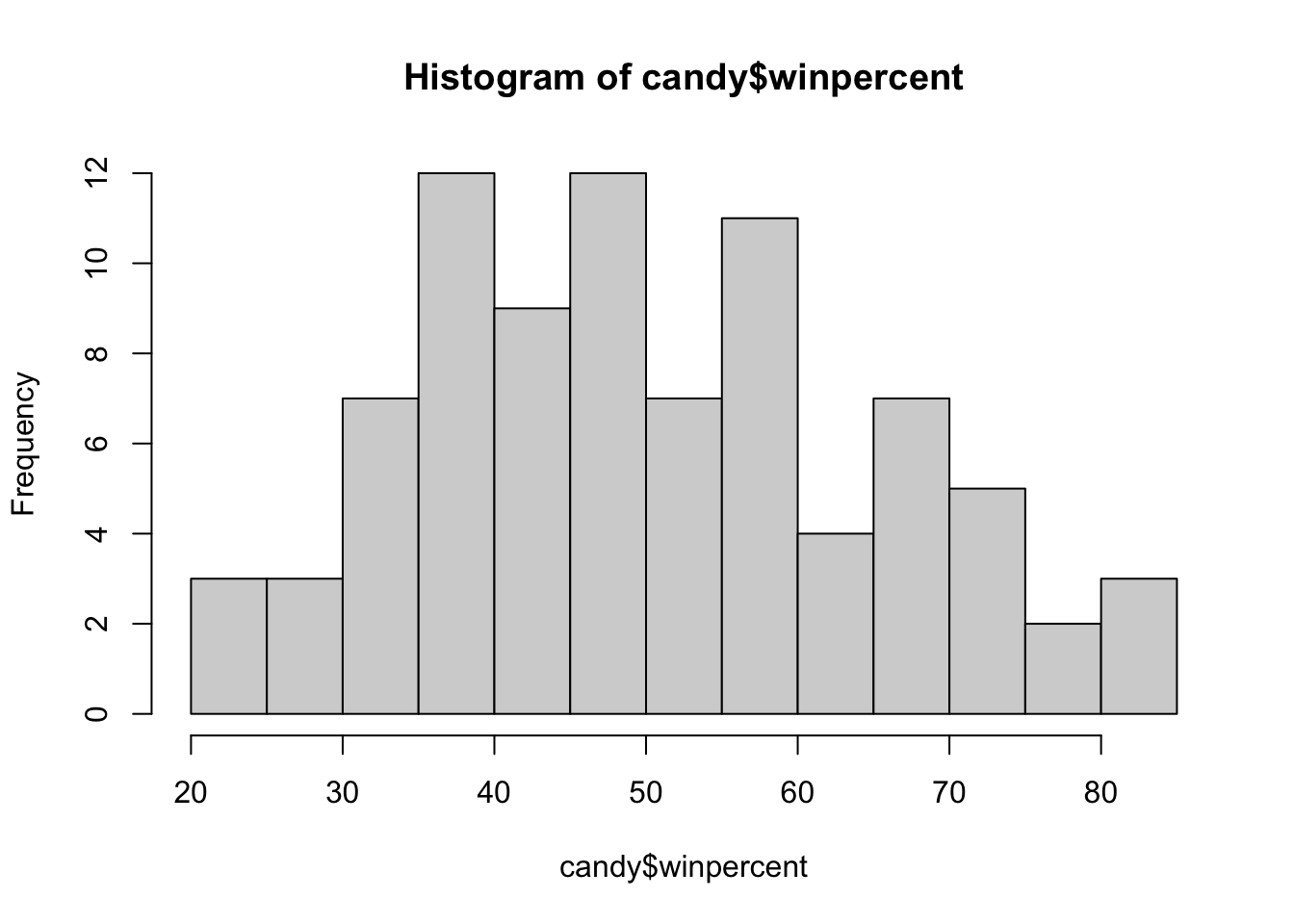
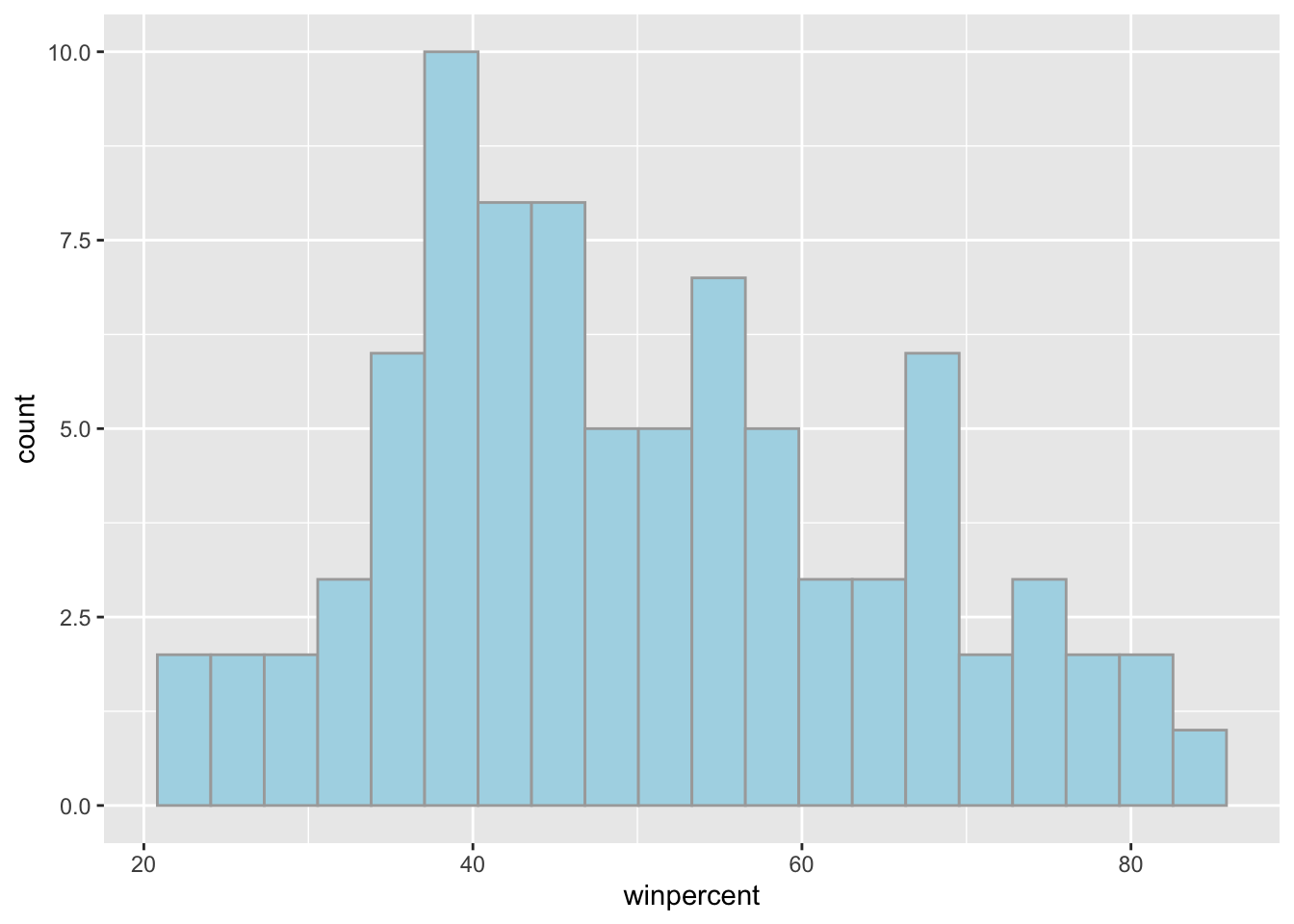
Q9. Is the distribution of winpercent values symmetrical?
No, it is not symmtrical.
Q10. Is the center of the distribution above or below 50%?
mean(candy$winpercent)
[1] 50.31676
median(candy$winpercent)
[1] 47.82975
The center of distribution is slightly below 50% taking the median values, but a mean value of around 50% suggests a right-skewed plot.
Q11. On average is chocolate candy higher or lower ranked than fruit candy?
Steps to solve this: 1. Find all chocolate candy in the dataset 2. Extract or find their winpercent values 3. Calculate the mean of these values 4. Find all fruity candy 5. Find their winpercent values 6. Calculate their mean vlaue
mean(candy$winpercent[candy$chocolate==1])
[1] 60.92153
mean(candy$winpercent[candy$fruity==1])
[1] 44.11974
median(candy$winpercent[candy$chocolate ==1])
[1] 60.8007
median(candy$winpercent[candy$fruity ==1])
[1] 42.96903
On average, chocolate candy is ranked higher than fruity candies. This is evident from the mean and median for winpercent both being around 60% for chocolate cnady.
Q12. Is this difference statistically significant?
Welch Two Sample t-test
data: choc and fruit
t = 6.2582, df = 68.882, p-value = 2.871e-08
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
11.44563 22.15795
sample estimates:
mean of x mean of y
60.92153 44.11974
This difference is statistically significant as indicated by the extremely small p value. A p value below 0.05 tells us that there is statistical signifiance. Chocolate has both a higher mean and median than fruity candies. Additionally, we have a 95% confidence interval.
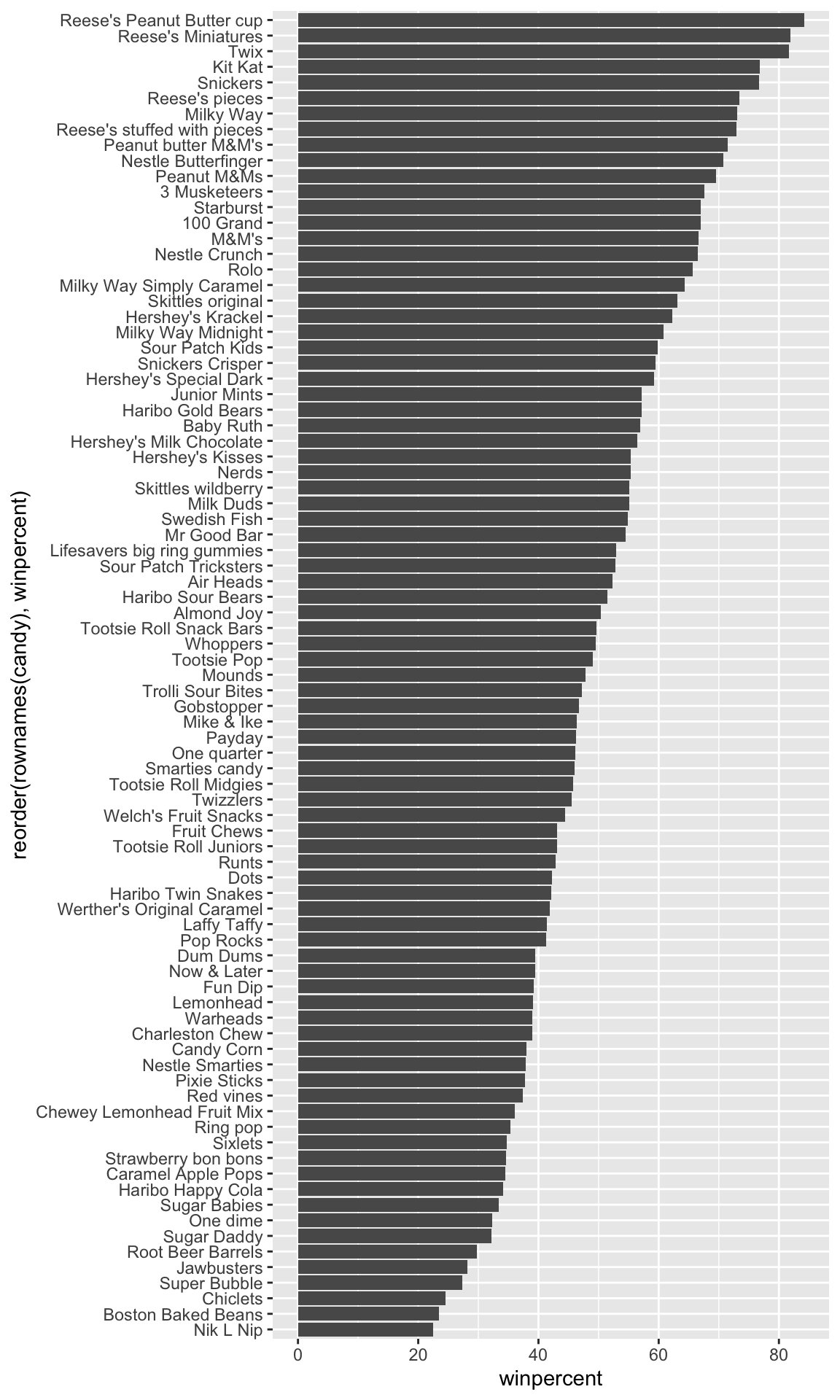
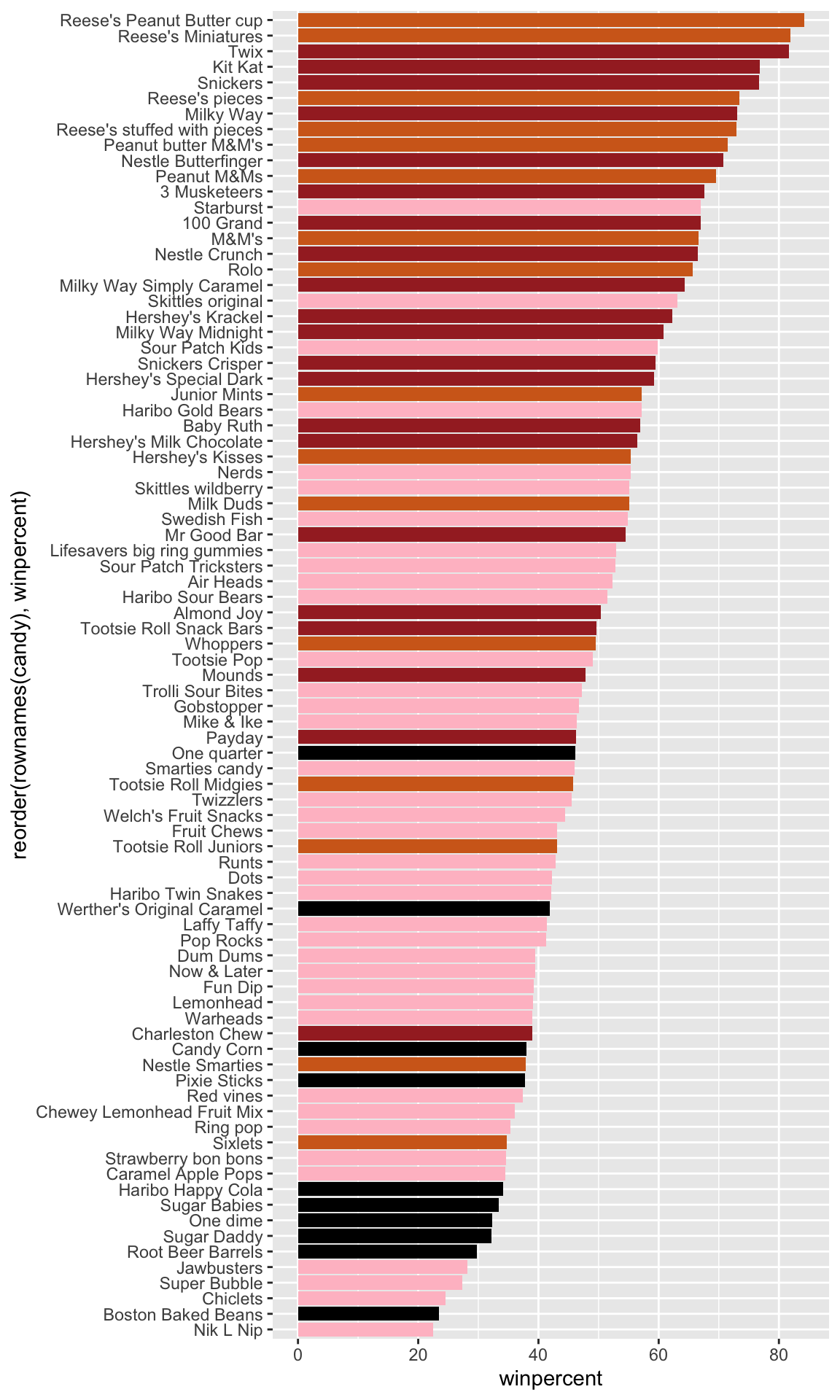
Overall Candy Rankings
Q13. What are the five least liked candy types in this set?
head(candy[order(candy$winpercent), ], n=5)
chocolate fruity caramel peanutyalmondy nougat
Nik L Nip 0 1 0 0 0
Boston Baked Beans 0 0 0 1 0
Chiclets 0 1 0 0 0
Super Bubble 0 1 0 0 0
Jawbusters 0 1 0 0 0
crispedricewafer hard bar pluribus sugarpercent pricepercent
Nik L Nip 0 0 0 1 0.197 0.976
Boston Baked Beans 0 0 0 1 0.313 0.511
Chiclets 0 0 0 1 0.046 0.325
Super Bubble 0 0 0 0 0.162 0.116
Jawbusters 0 1 0 1 0.093 0.511
winpercent
Nik L Nip 22.44534
Boston Baked Beans 23.41782
Chiclets 24.52499
Super Bubble 27.30386
Jawbusters 28.12744
The five least liked candy types in this data set are Nik L Nip, Boston Baked Beans, Chiclets, Super Bubble, and Jawbusters.
Q14. What are the top 5 all time favorite candy types out of this set?
Tootsie roll midgets are ranked highest in terms of winpercent for the least money.
Q20. What are the top 5 most expensive candy types in the dataset and of these which is the least popular?
order <-order(candy$pricepercent, decreasing =TRUE)top5exp <- candy[order, ][1:5, c("pricepercent","winpercent")]top5exp
pricepercent winpercent
Nik L Nip 0.976 22.44534
Nestle Smarties 0.976 37.88719
Ring pop 0.965 35.29076
Hershey's Krackel 0.918 62.28448
Hershey's Milk Chocolate 0.918 56.49050
top5exp[which.min(top5exp$winpercent), ]
pricepercent winpercent
Nik L Nip 0.976 22.44534
The top 5 most expensive candy types are Nik L Nip, Nestle Smarties, Ring pop, Hershey’s Krackel, and Hershey’s Milk Chocolate. Of these, Nik L Nip is the least popular.
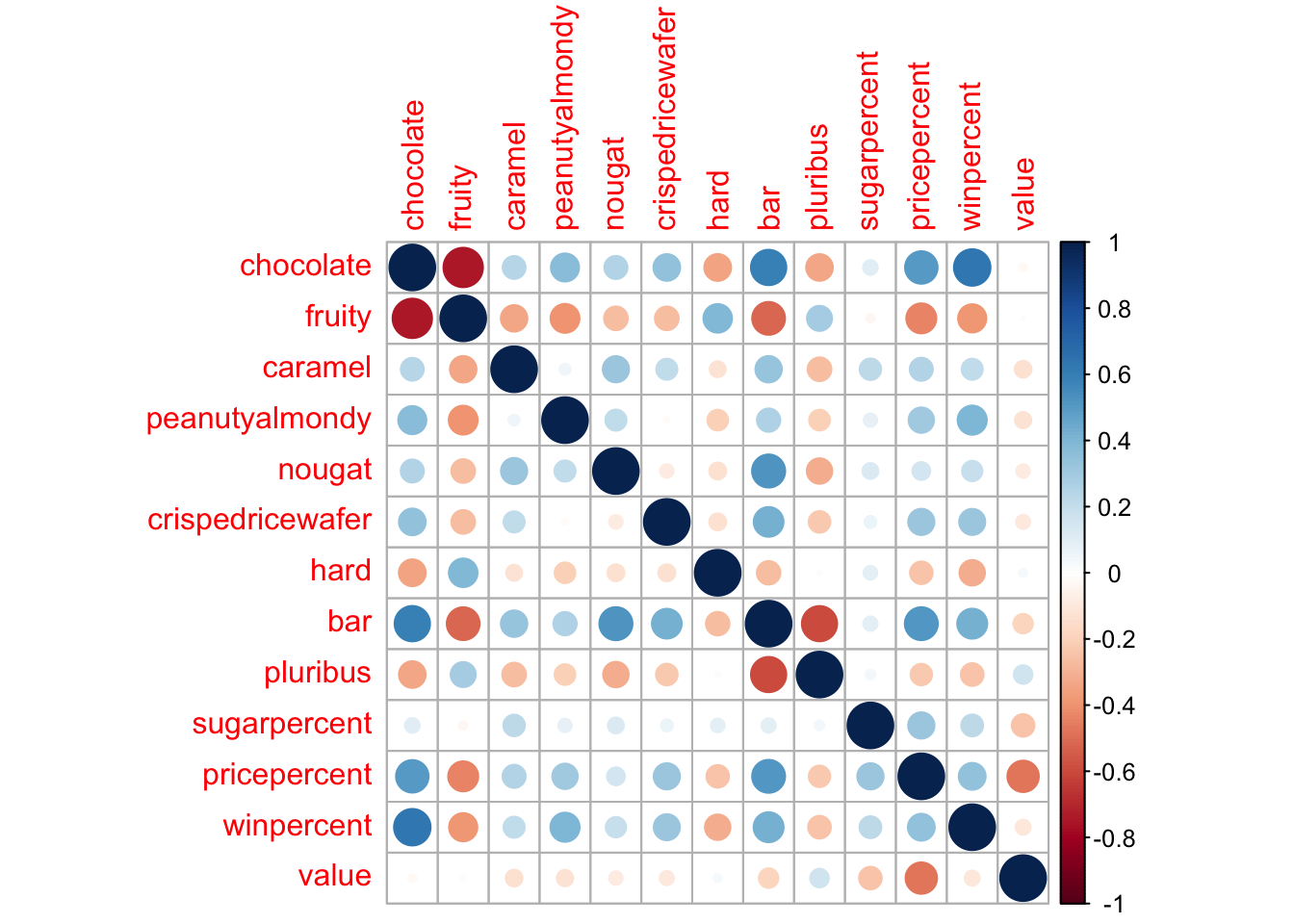
Exploring the correlation structure
Q22. Examining this plot what two variables are anti-correlated (i.e. have minus values)?